Prometheus Grafana 可视化监控服务器
Prometheus Grafana 可视化监控服务器
一、前言
Prometheus 是一个开源的监控解决方案,而 Grafana 是一个开源的度量分析和可视化工具。本文通过将 Prometheus 和 Grafana 结合使用,可以快速搭建一个漂亮的监控系统。
- Prometheus:Prometheus 是一个开源的系统监控和警报工具。它可以收集、存储和查询各种指标数据,并提供灵活的查询语言和警报规则。您可以使用Prometheus来监控各种系统和服务的性能和健康状况。
- Node Exporter:Node Exporter 是一个用于收集主机指标的 Prometheus Exporter。它可以运行在要监控的主机上,并提供关于主机硬件、操作系统和运行中进程的指标数据。Node Exporter 将这些指标暴露给 Prometheus 进行收集和存储。
- Grafana:Grafana 是一个开源的数据可视化和仪表盘工具。它可以连接到多个数据源,包括 Prometheus,并使用灵活的图表和仪表盘配置来展示数据。Grafana 提供了丰富的可视化选项,可以帮助您创建漂亮、交互式的监控仪表盘。
| 此次使用的设备及作用 | ||
|---|---|---|
| 设备 | 类型 | 作用 |
| A | Prometheus + Grafana | 集中所有机器采集的数据并使用 Grafana 展示 |
| B | Node Exporter | 收集本机数据 |
| C | Node Exporter | 收集本机数据 |
二、安装 Docker
此步骤仅在 A 机器上执行
1 | yum install -y docker-io |
三、安装配置 Prometheus
创建 prometheus.yml 配置文件并填入下方默认配置文件
1 | mkdir -p /root/Prometheus/Config/prometheus.yml |
1 | # 我的全局配置 |
也可以从 https://github.com/prometheus/prometheus/blob/master/documentation/examples/prometheus.yml 下载默认配置文件
启动 prometheus 容器
1 | docker run --name Prometheus \ |
现在访问其Web管理页面( http://localhost:9090 ),即可看到Prometheus服务被正确启动了
Prometheus 作为一个监控服务,主要负责收集、存储和展示监控数据。而实际的监控工作则是通过 Exporter 完成的。Exporter 可以看作是 Prometheus 服务的客户端,负责向 Prometheus 提供监控数据。根据不同的被监控目标,我们需要使用不同的 Exporter。在这个场景中,我们希望监控本机的运行状态,例如 CPU、内存、磁盘等参数。
在这种情况下,为了采集设备(A B C)的监控数据,我们需要下载并安装 Node Exporter。由于我们需要监控的是主机本身,一般不推荐使用 Docker 来部署 Node Exporter。
四、安装 Node Exporter
这一步 A、B、C 三台设备都需要安装
Node Exporter Github 地址:https://github.com/prometheus/node_exporter
4.1 创建 Node_Exporter
1 | mkdir -p /root/Prometheus/Node_Exporter |
4.2 下载 Node Exporter
1 | wget https://github.com/prometheus/node_exporter/releases/download/v1.6.0/node_exporter-1.6.0.linux-amd64.tar.gz -O - | tar -xzvf - |
4.3 动 Node Exporter
1 | cd node_exporter-1.6.0.linux-amd64/ |
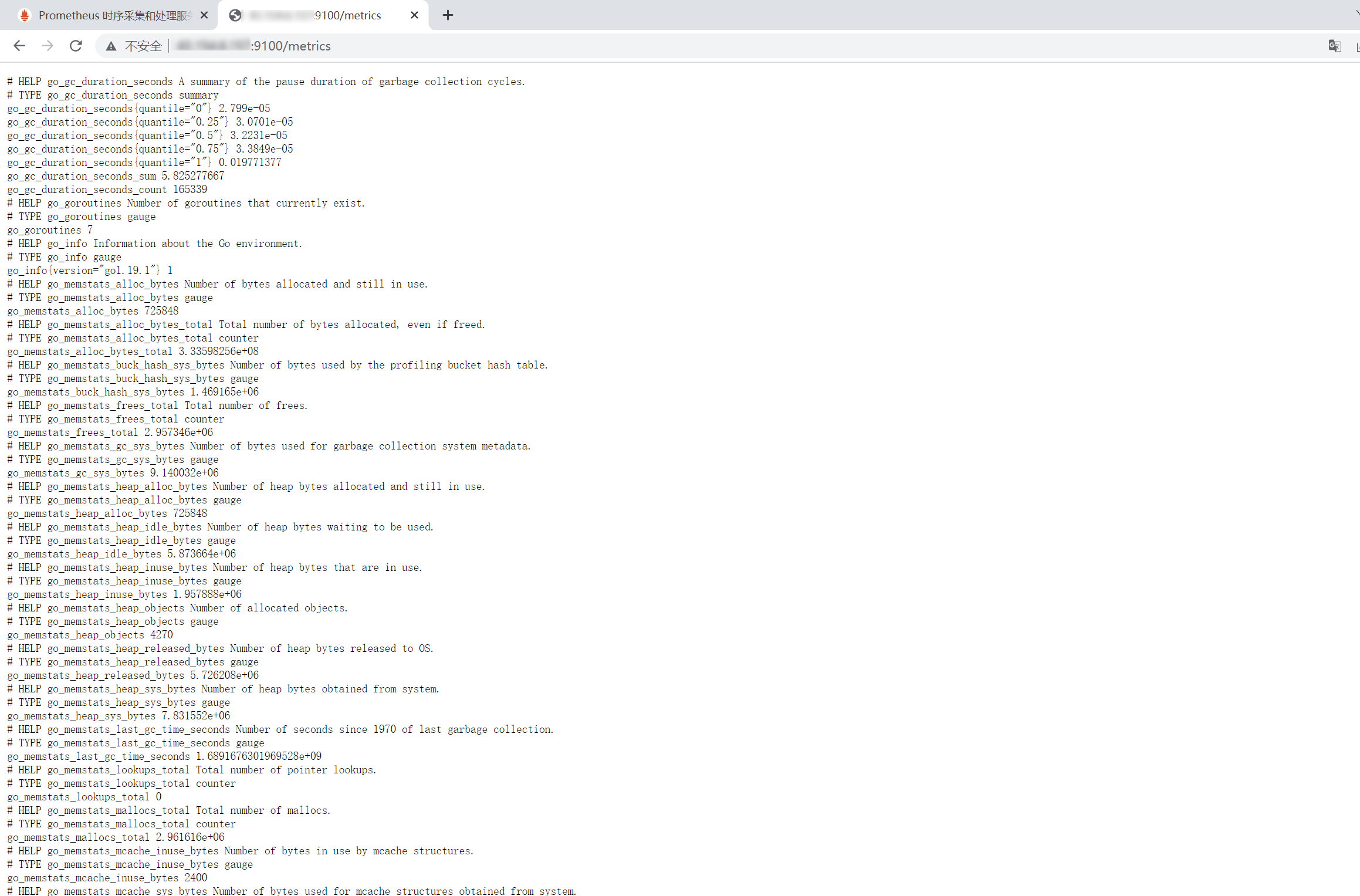
现在我们的 Node Exporter 已经成功启动,并运行在 9100 端口上。我们可以通过访问 http://IP:9100/metrics 来直接查看 Node Exporter 采集的监控数据。
4.4 修改 prometheus 配置文件
这时只需在 Prometheus 服务的配置文件 prometheus.yml 中添加相应的配置,在 scrape_configs 下添加一个名为 “TX HongKong” 的 job,并在 targets 中填写对应的 IP 地址,来收集 Node Exporter 的监控数据。这样,Prometheus 将定期从指定的 IP 地址获取监控数据,并将其存储起来以供后续分析和查询。
1 | # A scrape configuration containing exactly one endpoint to scrape: |
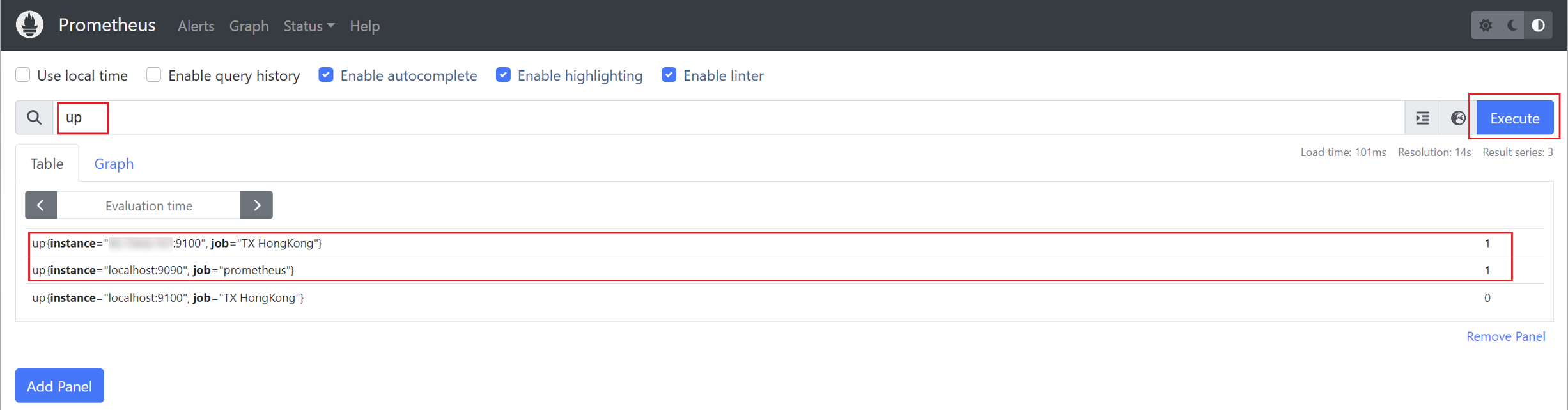
为了查看刚刚添加的 job 是否正常工作,需要可以重启 Prometheus 服务,并访问其 Web 管理页面(http://localhost:9090)。在查询输入框中输入 up,然后点击 “Execute” 按钮。这样,将会看到一个包含我们刚刚添加的 job 的结果。其中,1 表示正常,0 表示异常。通过这种方式,可以确认新添加的 job 是否成功运行并提供了监控数据。
4.5 Node Exporter 持久化
我们结束终端 Node Exporter 进程就断开,所以我们需要让它持续运行,并且设置自启动
- 创建 Node Exporter 的 systemd 服务单元文件:
在终端中使用文本编辑器创建一个名为node_exporter.service的文件:
1 | sudo nano /etc/systemd/system/node_exporter.service |
在文件中添加以下内容:
确保将下方
/root/Prometheus/node_exporter-1.6.0.linux-amd64/node_exporter替换为你实际的 Node Exporter可执行文件路径。
1 | [Unit] |
- 重新加载systemd服务配置:
1 | sudo systemctl daemon-reload |
- 启动Node Exporter服务:
1 | sudo systemctl start node_exporter |
检查服务状态:
如果一切正常,应该看到Node Exporter服务正在运行。
1 | sudo systemctl status node_exporter |
- 设置开机自启动:
1 | sudo systemctl enable node_exporter |
现在,Node Exporter 将持久化运行,并在系统启动时自动启动。为了管理和监控 Node Exporter 服务,可以使用 systemd 命令。通过 systemd,可以轻松地控制 Node Exporter 的启动、停止和重启,并确保其在系统启动时自动启动。
五、安装配置 Grafana
事实上,Prometheus 提供了一个简单的可视化界面,即 Prometheus UI。然而,它的功能相对简单,无法实时关注监控指标的变化趋势。因此,我们选择使用 Grafana 作为可视化解决方案。Grafana 是一个通用的可视化工具,也支持与 Prometheus 集成。为了使用 Grafana,我们可以直接拉取 Grafana 镜像并启动一个 Grafana 容器,从而快速搭建起 Grafana 的环境。
5.1 运行 Grafana 容器
1 | # 拉取镜像 |
现在,你可以通过访问 http://IP:3000 来访问 Grafana 的 Web 页面。初始账号和密码均为 admin。
请注意,在首次登录时,会被要求强制设置一个新密码。这是为了增强安全性。请按照界面上的提示进行操作,设置一个新的密码。一旦完成首次登录并设置了新密码,就可以开始使用 Grafana 来创建仪表盘、可视化监控数据,并进行更多高级配置和操作了。
下面为首次登陆成功后显示界面
5.2 添加数据源
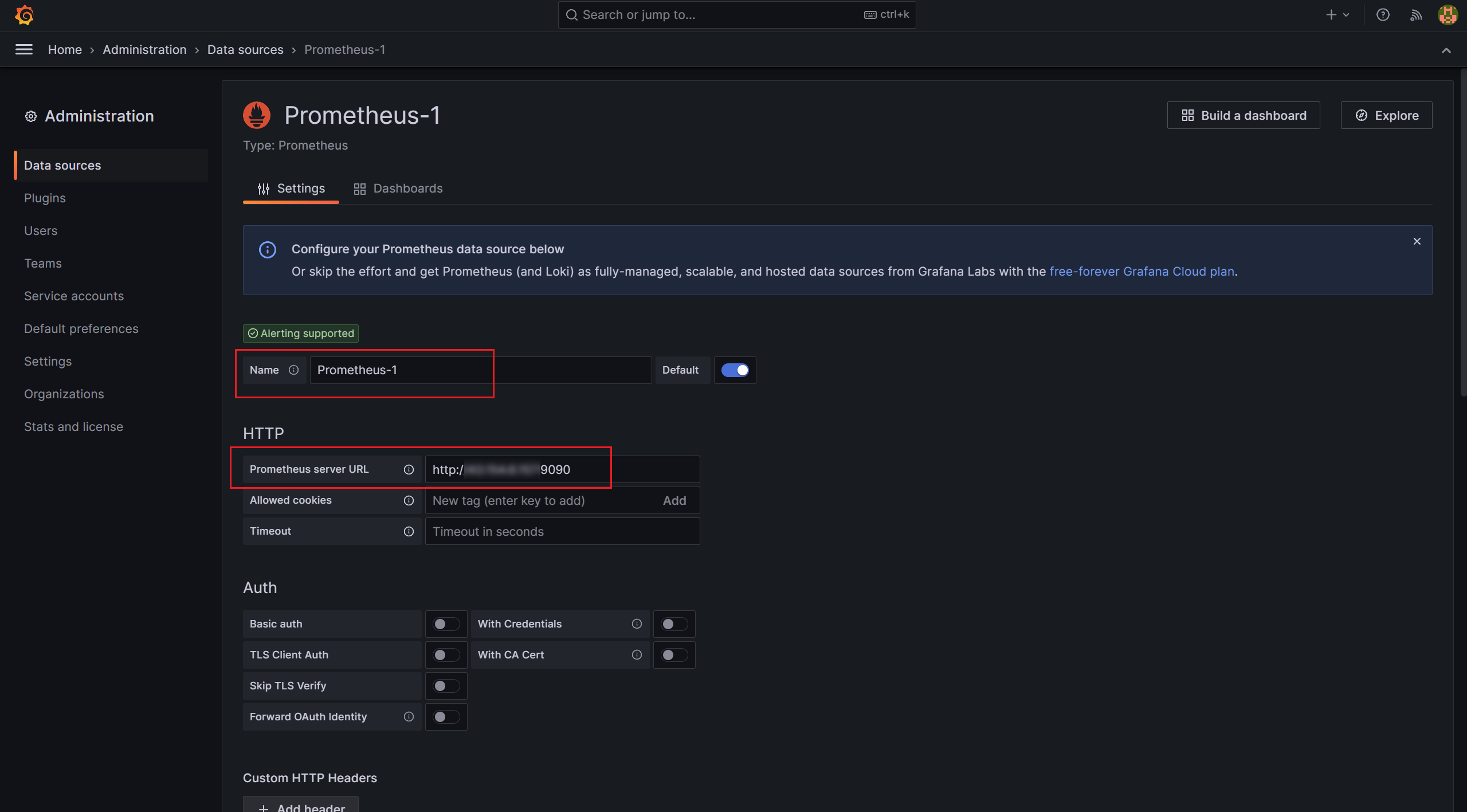
首先,为了在 Grafana 中使用 Prometheus 数据,我们需要添加一个 Prometheus 类型的数据源。
依次选择: Configuration(配置)→ Data Sources(数据源)→ Add data source(添加数据源)
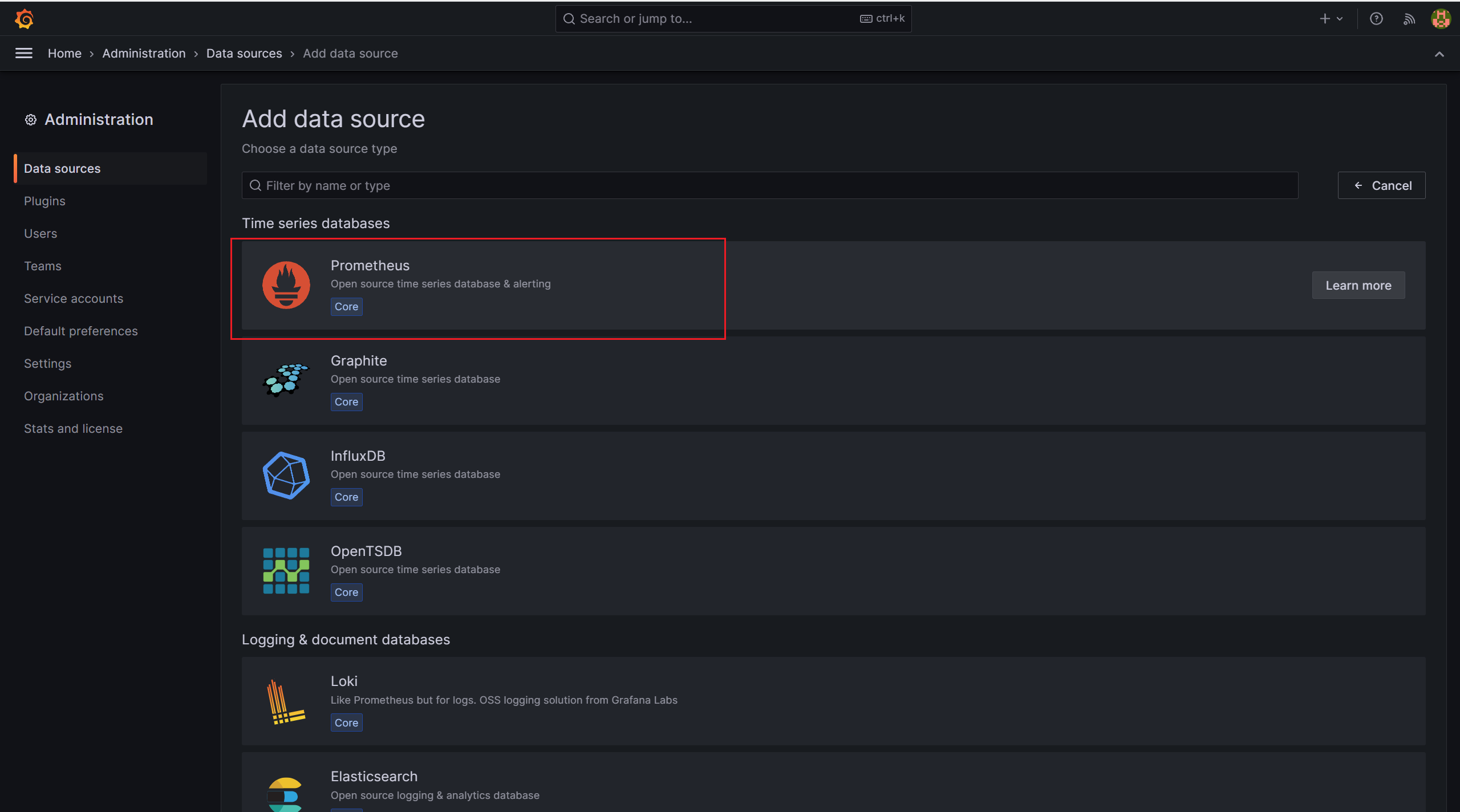
我们数据源类型是 Prometheus,所以下面选择 Prometheus
现在设置该数据源的名称、URL地址 保存即可

5.3 添加监控仪表盘
数据源添加完成了,现在我们需要添加一个监控所需的仪表盘。在 Grafana 中我们可以自定义各种监控所需的仪表盘,但是如果完全自己搭建较为麻烦。为此我们可在现有模板的基础上根据需要进行微调。
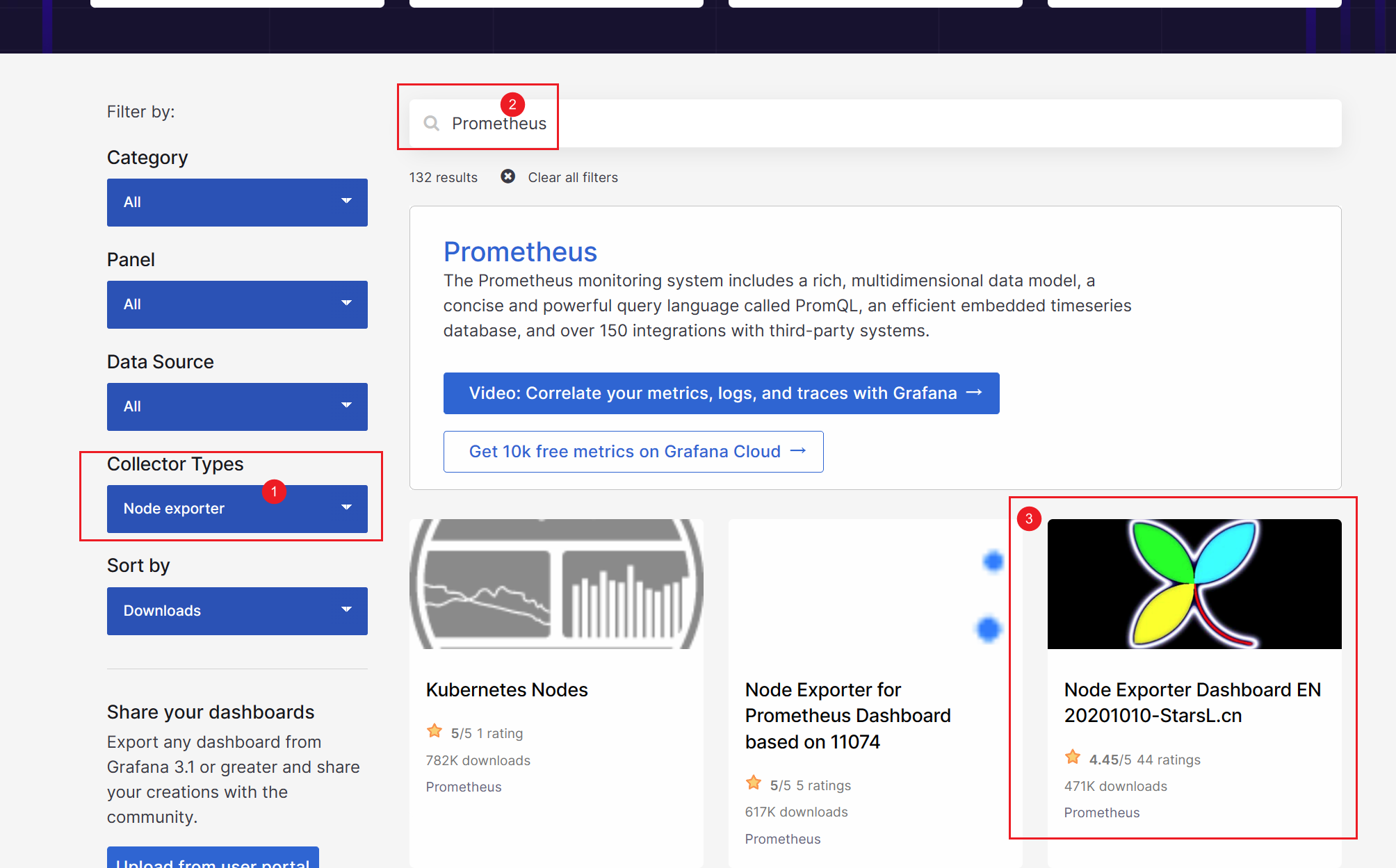
Grafana 仪表盘网站:https://grafana.com/grafana/dashboards/
过滤出适用 Node Exporter 类型的相关模板,这里我们选择支持中文的模板,然后复制选择的模板 ID—8919
现在,回到 Grafana 的 Web 管理页面,我们需要导入所需的模板
操作:Home(首页)→ Dashboards(仪表盘)→ New(新建)→ Import(导入)
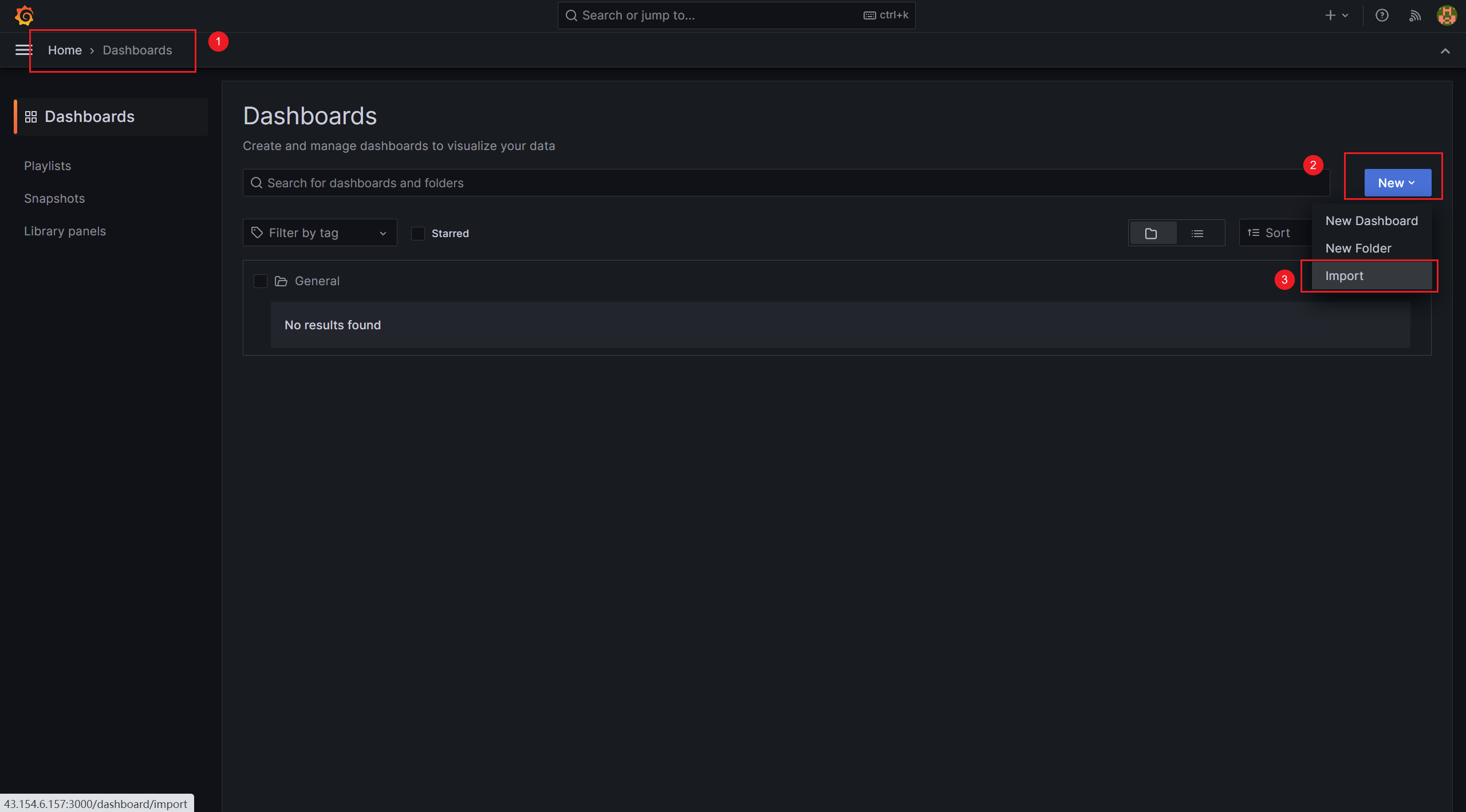
填写模板ID
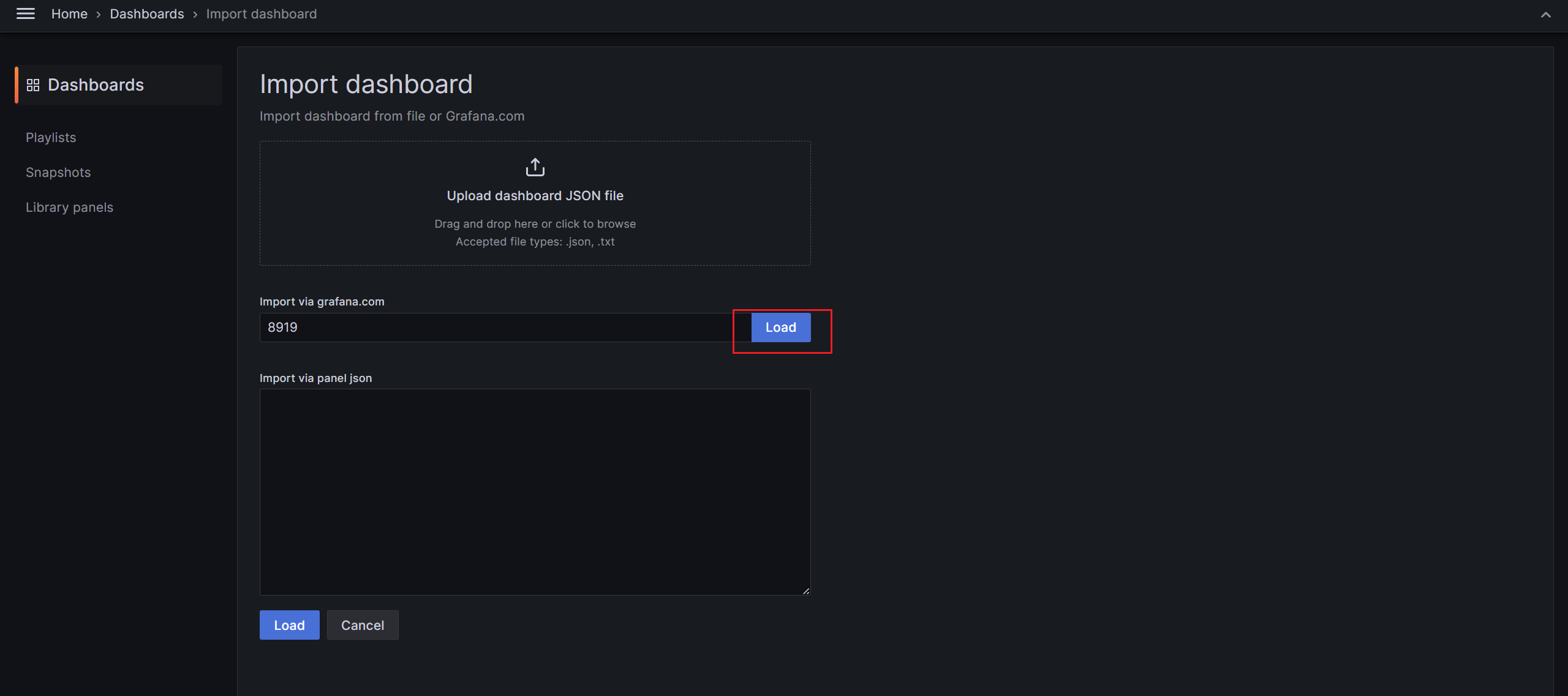
选择数据源,继续导入
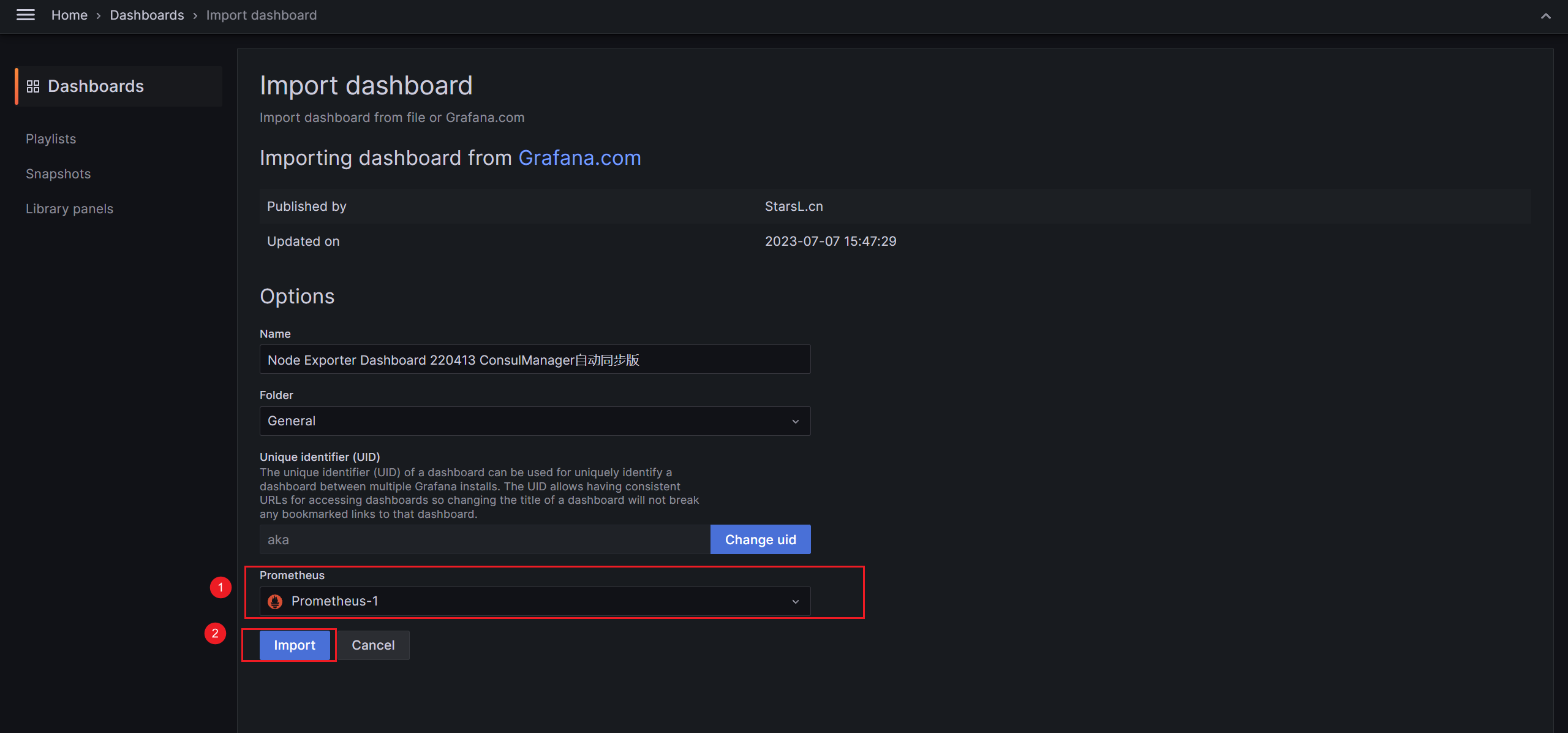
至此,一个仪表盘就创建完成了,效果如下所示

5.4 添加 B、C 设备监控信息
但是目前只添加了 A,还有 B、C 两台机器,单B和C安装好 Node Exporter 后,只需要在 Prometheus 机器上添加即可(Prometheus安装在A设备)
Prometheus 配置文件示例:
1 | # 一个包含一个端点的抓取配置: |
在配置文件添加B C的设备后,需要重启 Prometheus ,使用下方命令:
1 | docker restart prometheus |
六、Node Export 设置密码
现在我们直接访问任意一台 Node Export 的监控地址都可以直接看到数据,这样相当于在裸奔。
为了提高安全性,可以使用基础认证(用户名和密码)的方式访问 Exporter 采集指标的地址。这样,只有提供正确的用户名和密码的用户才能够访问到被监控端的接口,并采集监控数据。这种方式可以有效地增加访问的安全性和权限控制。
6.1 安装 htpasswd
yum 命令安装 htpasswd:
1 | yum install httpd-tools –y |
apt 命令安装 htpasswd:
1 | sudo apt install apache2-utils -y |
6.2 生成一个基于 bcrypt 算法的密码哈希值
使用下方命令,输入两次密码即可生成:
1 | htpasswd -nBC 12 '' | tr -d ':\n' |
1 | root@ubuntu-sfo3:~# htpasswd -nBC 12 '' | tr -d ':\n' |
$2y$12$BcbqEuwZCz5mHS.kxXV46uvyKvA6J6UV4xOt3aj5HQjoCdOFcmZL2为加密的密码
6.3 创建 node exporter配置文件
进入node_exporter执行文件路径下,创建其配置文件
1 | cd /root/Node_Exporter/node_exporter-1.6.0.linux-amd64 |
填入下方内容(其中用户名就是loki,分号后面就是上面创建的密码):
1 | basic_auth_users: |
6.4 修改 export
现在让 export 引用这个配置文件:
1 | sudo nano /etc/systemd/system/node_exporter.service |
1 | [Unit] |
保存并关闭服务配置文件,重新加载服务配置文件以使更改生效:
1 | sudo systemctl daemon-reload |
重新启动 Node Exporter 服务以应用更改:
1 | sudo systemctl restart node_exporter |
现在,Node Exporter 开放的9100要求提供用户名和密码才能访问。
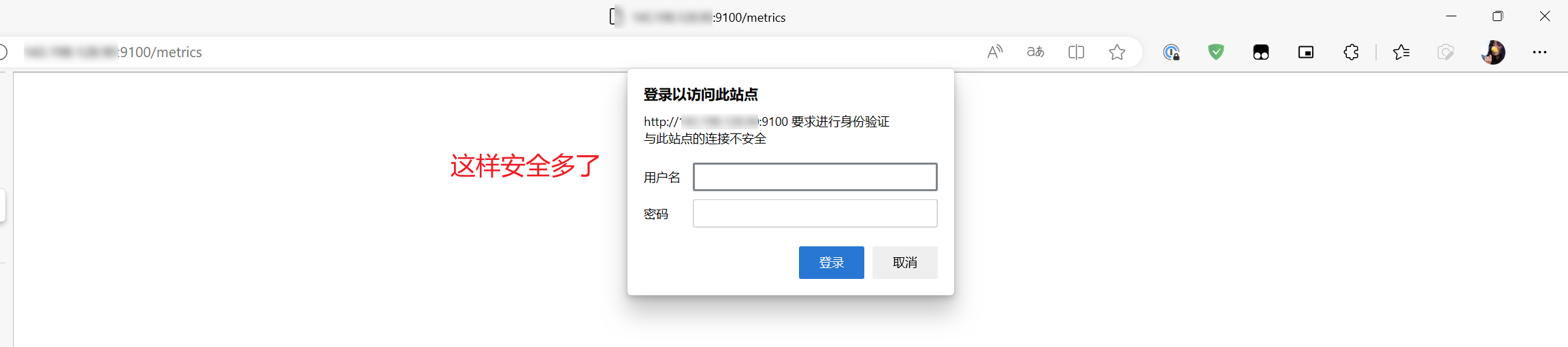
此时打开 Prometheus 的 Targets 页面,也会看到当前提示 401 ,无法抓取 metrics 。

6.4 配置 Prometheus 使用 Basic Auth
接下来,需要修改 Prometheus 的配置文件,为其增加 basic_auth 用户名密码的配置项即可(在A设备编辑):
1 | nano /root/Prometheus/Config/prometheus.yml |
1 | - job_name: "A" |
重启 Prometheus
1 | docker restart prometheus |
现在刷新 Prometheus 的 Targets 页面,就可以看到已经正常抓取 metrics 了。

七、Prometheus 设置密码
7.1 反代 Prometheus
为了安全和方便访问,可以我使用了一个域名反向代理本机的 Prometheus ,并设置了SSL,下面的操作将在此基础上执行
7.2 新建密码
上面已经安装了htpasswd,这里就不需要安装,创建密码(loki 是用户名):
1 | mkdir -p /usr/local/src/nginx/ |
运行命令后,会要求你连续输入两次密码。输入成功后,会提示已经为loki 这个用户添加了密码。
查看下生成的密码文件的内容:
1 | cat /usr/local/src/nginx/passwd |
loki:$2y$12$1J53DGzFE0.4DoGUnEPy1um1bhQJ4UwXcoHMOYXjBR6vseLTzv0t6
7.3 修改 nginx 配置文件
找到 nginx 配置文件,因为我们要对整个站点开启验证,所以在配置文件中的第一个 server 修改如下:
1 | server { |
以上都配置无误后重启 nginx,然后重新访问你的站点,如果出现需要身份验证的弹窗就说明修改成功了。
登录错误

7.4 Grafana 添加访问密码
返回 Grafana 设置,打开 Basic auth 输入新建的用户名和密码即可
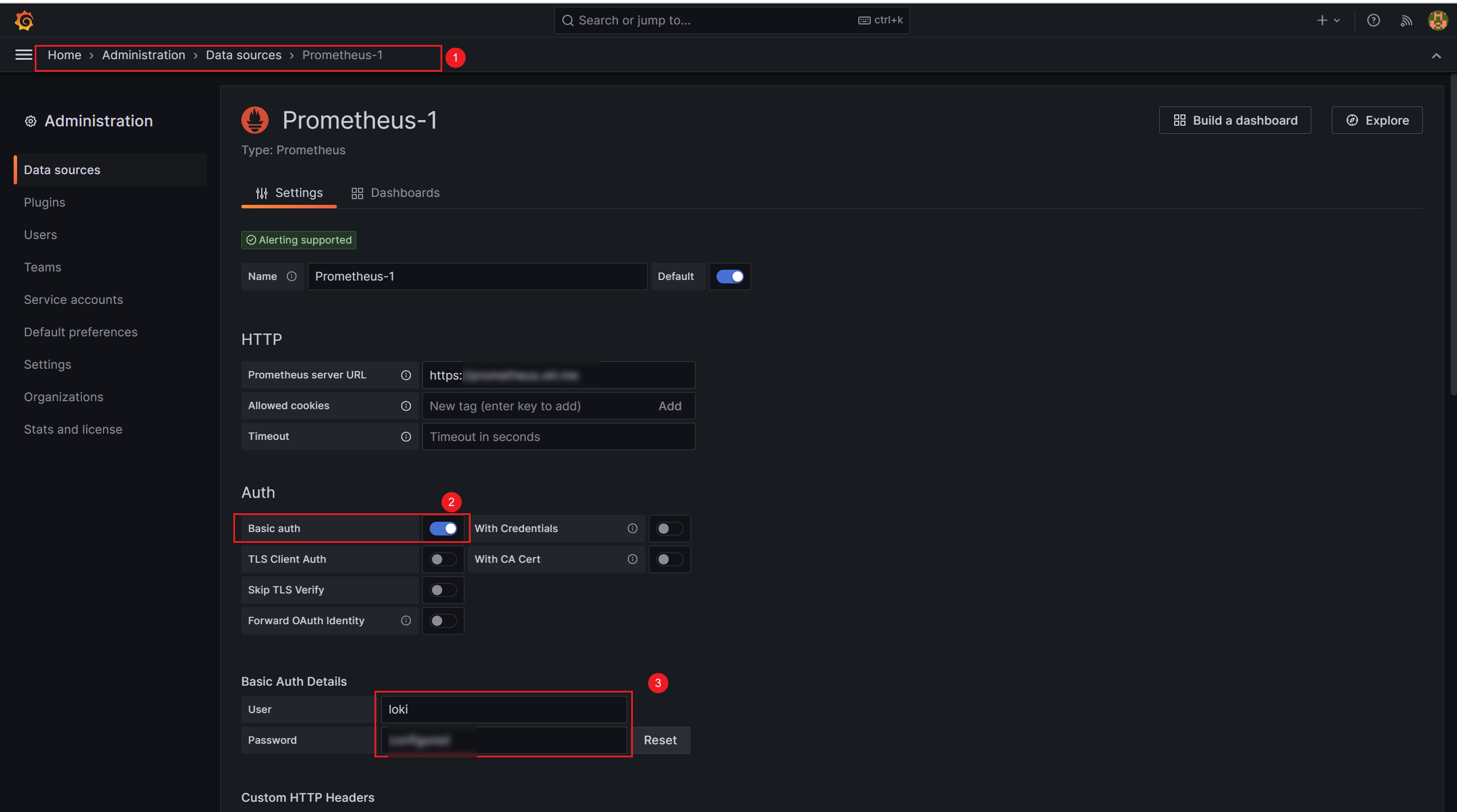
八、Ubuntu nftables 防火墙规则(可选)
如果你觉得设置密码太麻烦了,那其实可以选择设置防火墙,直接设置9100端口白名单,只允许A设备访问
编辑 nftables 文件:sudo nano /etc/nftables.conf
重载 nftables 文件:sudo nft -f /etc/nftables.conf
1 | #!/usr/sbin/nft -f |
八、最后
本章到此结束,其实 Node Export 还可以添加 TLS,后面将基于此文,监控 Docker、MySQL、Nginx