解释: enable=1:表示启用这个源 gpgcheck=1:表示对这个源下载的rpm包进行校验 repo_gpgcheck=0:某些安全性配置文件会在 /etc/yum.conf 内全面启用 repo_gpgcheck,以便能检验软件库中数据的加密签署,如果repo_gpgcheck设置为1,会进行校验,就会出现报错[Errno -1] repomd.xml signature could not be verified for kubernetes,所以这里设为0
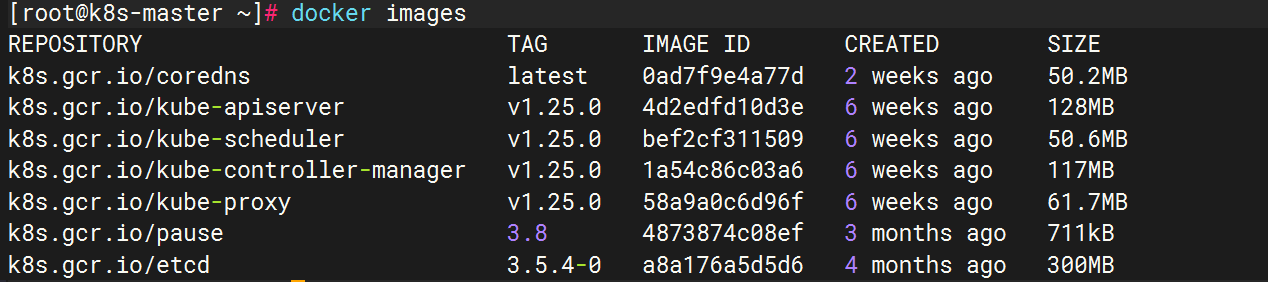
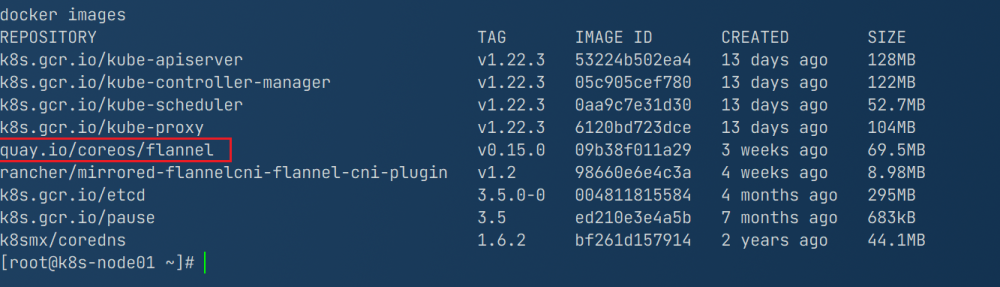
for imageName in ${images[@]} ; do docker pull registry.aliyuncs.com/google_containers/$imageName docker tag registry.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName docker rmi registry.aliyuncs.com/google_containers/$imageName done
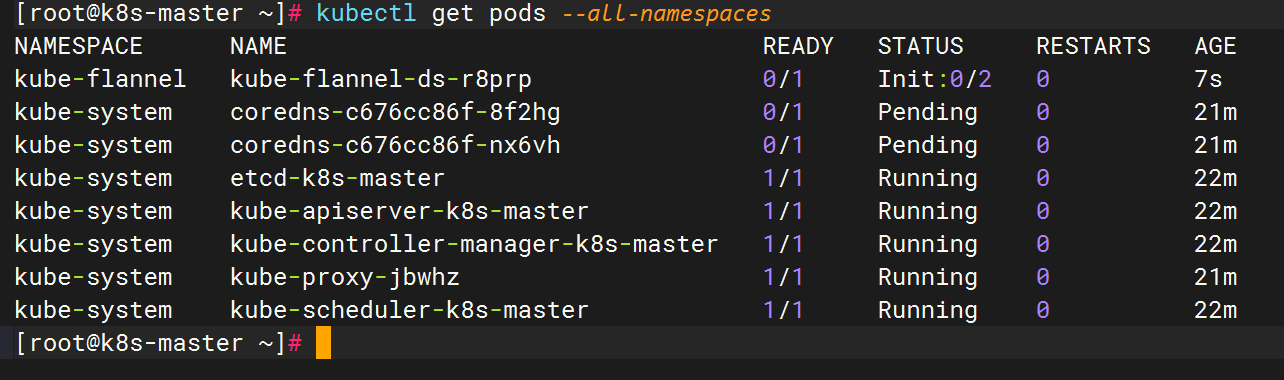
[init] Using Kubernetes version: v1.25.0 [preflight] Running pre-flight checks error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR CRI]: container runtime is not running: output: E1007 15:56:10.546831 3659 remote_runtime.go:948] "Status from runtime service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService" time="2022-10-07T15:56:10+08:00" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService" , error: exit status 1 [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher [root@k8s-master ~]# rm /etc/containerd/config.toml rm: remove regular file ‘/etc/containerd/config.toml’? y [root@k8s-master ~]# rm /etc/containerd/config.toml rm: cannot remove ‘/etc/containerd/config.toml’: No such file or directory
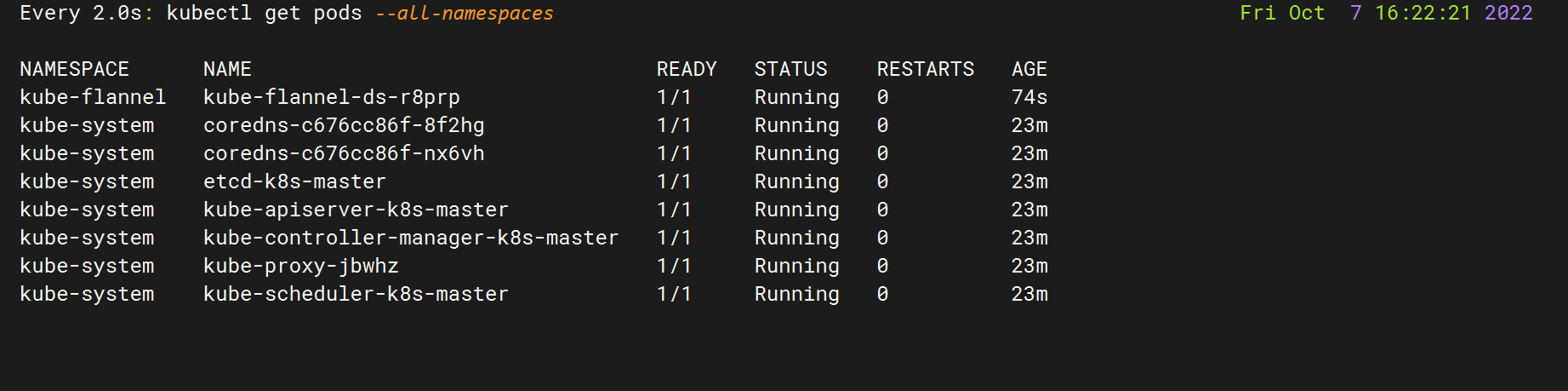
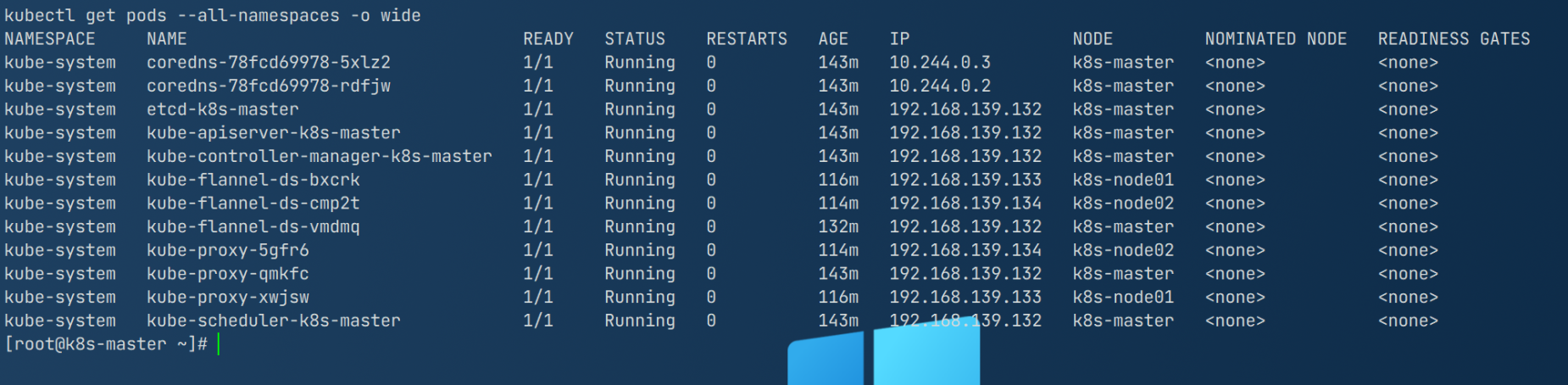
[root@k8s-master ~]# kubeadm init \ > --apiserver-advertise-address=192.168.100.130 \ > --image-repository registry.aliyuncs.com/google_containers \ > --kubernetes-version=v1.25.0 \ > --service-cidr=10.96.0.0/12 \ > --pod-network-cidr=10.244.0.0/16 [init] Using Kubernetes version: v1.25.0 [preflight] Running pre-flight checks [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [k8s-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.100.130] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [k8s-master localhost] and IPs [192.168.100.130 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [k8s-master localhost] and IPs [192.168.100.130 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 11.503332 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node k8s-master as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers] [mark-control-plane] Marking the node k8s-master as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule] [bootstrap-token] Using token: c7y1ii.zzpnb7zxofdxjczp [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy
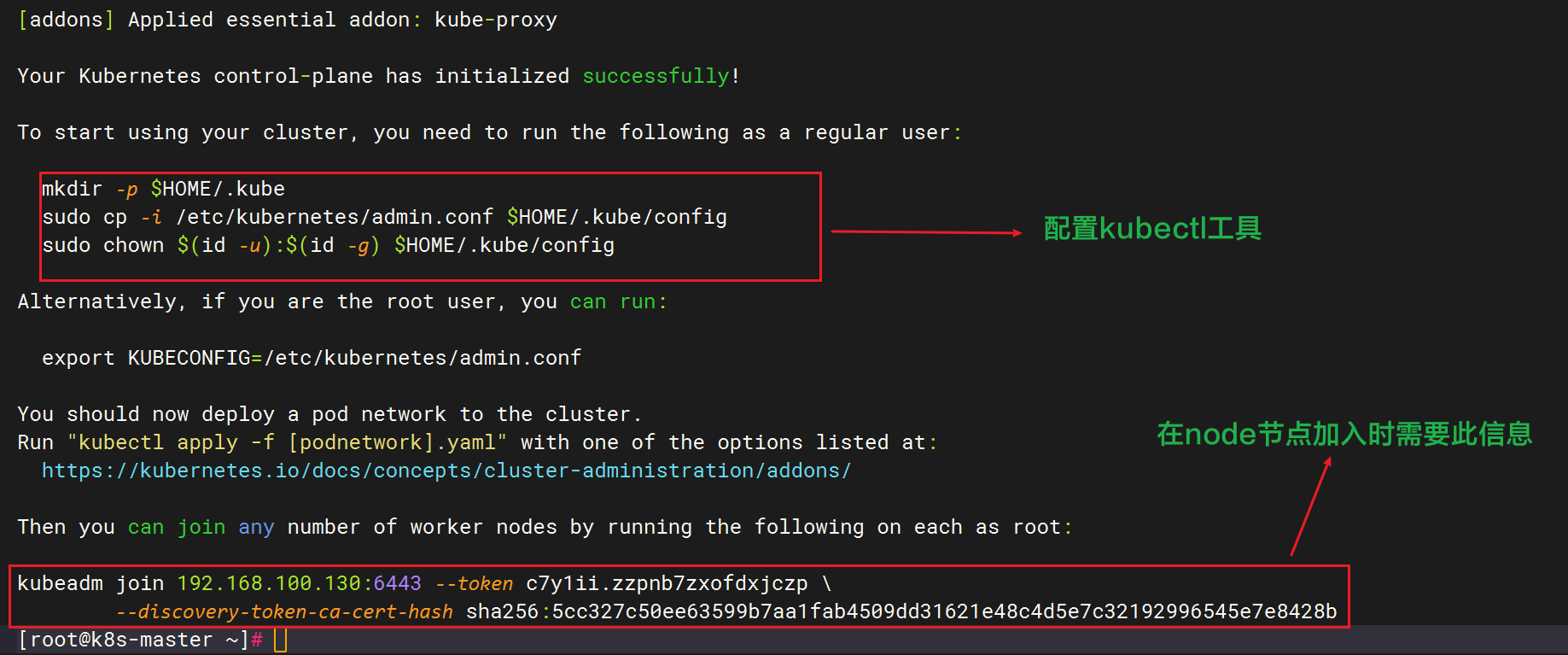
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
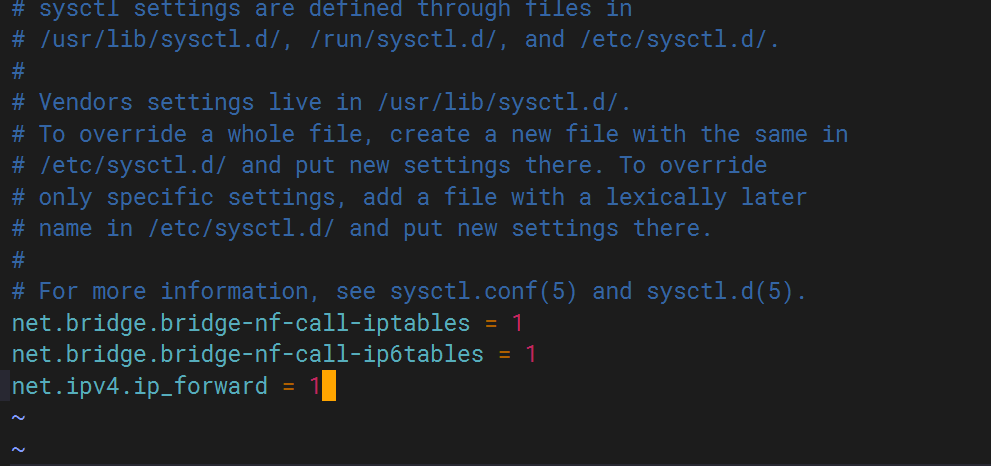
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directory